Shippable はだいぶ前に JFrog 傘下になり JFrog Pipelines と Shippable の2つのサービスが提供されていました。
Shippable のサービス提供も続けていくよとされていましたが、とうとう終了となりました。
(マイニングの影響もあったのかはわからないけど、あれは困ったものですな)
The Next Step in the Evolution of Shippable: JFrog Pipelines
いつまで見られるかわからないですが、こちらは引越し前の Shippable ビルド履歴です。
https://app.shippable.com/github/srz-zumix/iutest/dashboard/history
5/3 まで元気に動いてました。お疲れ様でした。
さて、Shippable は終了となりましたが、JFrog Pipelines に移行できるようなのでやってみました。
移行するのは以下のリポジトリです。
https://github.com/srz-zumix/iutest
Pricing
その前に気になるのはお値段ですよね。
Shippable のときは↓な感じでしたが、
Unlimited builds for public projects
150 builds/month for private projects
Forum support
(Shippable がどんなのだったかは拙著「あつまれCIサービス」を読んで頂くのもありですよ)
JFrog Pipelines はこんな感じ。
ビルド時間無制限はこのご時世ではもう無理なんでしょうねぇ
それでも2000分/月使えるのはありがたいです。(Travis CI も毎月付与にならないかなぁ)
プランの確認ができたので、早速登録して使ってみましょう。
Get Started
Start for free などからリンク開くと以下のようなページが開きます。
日本語ページもあるのでそちらからも登録できます。
クラウドプロバイダー(Select your cloud provider)
クラウドプロバイダーの選択が出てきて、ちょっと本当に無料の範囲でできるのかな?と不安になりますが、No Credit Card だし大丈夫だと信じて進みます。
(実際問題ない)
自分はどれもあまり詳しくないのですが、まだ多少知ってるという理由で Google Cloud を選択しました Google 選んだつもりでしたが AWS を選んでました(2021/08/02 追記)。
サーバーの詳細(Server Details)
お客様詳細情報(Create your Credentials)
メールアドレスとパスワードを記入します。
パスワードは大文字・小文字、数字、記号を含める必要があります。
ユーザー詳細(User Details)
氏名を入力します。英語(アルファベット)で記入する必要があるようです。
PROCCED して完了。
問題がなければ「JFrog Free Subscription Activation」というタイトルでメールが来ます。
「Click here to activate your JFrog subscription」のリンクを開いてアクティベートします。
待ちます。
完了したらログインできるようになるので Login しましょう。
ログインしたら↓のようなダッシュボードが開くと思います。
セットアップ
JFrog には Pipelines の他にもプロダクトがありますが、今回使うのは Pipelines です。
まずは左側メニューから「Pipelines」を選択。「Clik to Activate」をクリック。
待ちます。
君はそのページ見れないよ。とエラーっぽいメッセージが出ますが、admin なはずなのでそんなわけはありません。
おそらくまだセットアップ中なのでしょう。待ちます。
・・・zzz
一晩寝かせたことでアクセスできるようになってました。(少し時間がかかると思ったほうがよさそうですね)
※一度ログアウトしてログインし直すと見えるようです(2021/08/02 追記)
Pipelines が使えるようになったので設定の続きをしていきます。
今回は Pipelines だけまずは使いたいので Step 2/3 はスキップして「Step 4: Define a pipeline」から始めます。
Artifactory を Integrations に追加
※成果物を特に扱わない、パイプラインを試してみるだけ、という場合は飛ばして OK
先に、Artifactory 用の API Token を JFrog の User Profile から払い出しておきます。
右上のユーザーメニューから「Edit Profile」を開き、ログインパスワードを入力して Unlock します。
Unlock すると操作できるようになるので「Authentication Settings」の「Generate API Key」をクリックします。
API キーが生成されたら、コピーしておきましょう。
つづいて、「Administraion」タブの「Pipelines」から「Integrations」を開き、右上の「+ Add an Integration」をクリックします。
Pipeline から利用するので「Usage」は Pipelines を選択。
名前は任意、「Integration Type」に Artifactory を選択します。
URL と User はデフォルトのままで良いと思います。
API Key に先程コピーしたものをペーストし、「Create」をクリックして完了です。
「Assign Pipelines to this Integration」はとりあえず Any で OK です。制限かけたい場合はチェックを外すと許可する source を選択できます。(画像にはいくつか source がありますが、現時点ではまだ source 登録してないので空っぽだと思います)

GitHub を Integrations に追加
次に GitHub を Integrations に追加します。
Artifactory と同様に、右上の「+ Add an Integration」をクリックします。
Pipeline から利用したいので「Usage」は Pipelines を選択。
名前は任意、「Integration Type」に GitHub を選択します。
最後に GitHub のパーソナルアクセストークンを作成して入力したら「Create」ボタンを押します。
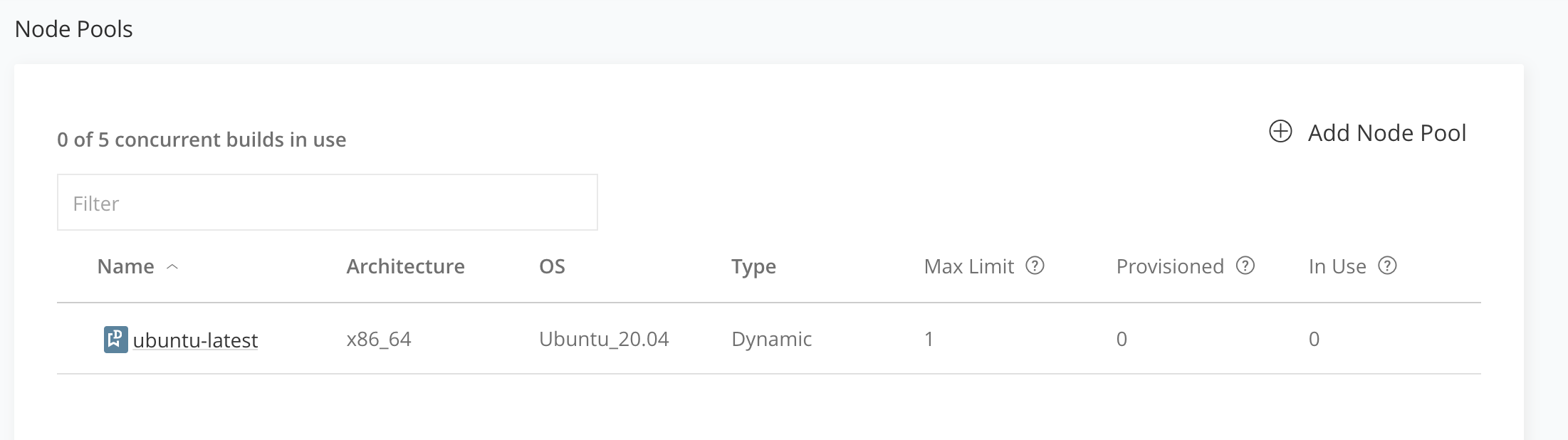
Node Pool にノード追加
次に実行環境を用意しておく必要があるので登録します。
「Administraion」タブの「Pipelines」から「Node Pools」を開き、右上の「+ Add Node Pool」をクリックします。
下記画面のようになるので、名前の入力とイメージを選択します。
選択可能なイメージは Ubuntu/CentOS/Windows があります。
Node Limits は同時に起動可能なノード数の制限です。1 にした場合、このノードを使うジョブは 1 つずつ順番に実行されます。
Node Idle Interval はノードが停止するまでの時間です。
ノードは常に起動しているのではなく必要なときに起動します。
commit でジョブを実行する場合、インターバルが短いと都度都度ノードを起動することになるので、使い方に合わせて時間を調整しましょう。
ちなみに、有料プランでは静的ノードが使えます。
Pipeline source を追加
ノードの準備ができたらパイプラインを登録しましょう。
「Administraion」タブの「Pipelines」から「Node Pools」を開き、右上の「+ Add Pipeline Source」をクリック、「From YAML」を選択します。

パイプライン YAML を PR で追加したいので、「Multi Branch」を選択します。
「SCM Provider」は上で追加した GitHub のインテグレーションを選びます。
ほどなくリポジトリが選択可能になるので、目的のものを選択。
「Exclude/Include Branch Pattern」で YAML の Sync をするブランチの対象を制御できます。
最後に、YAML ファイルのパスを入力して「Create Source」しましょう。
(JFrog では YAML ファイルは任意の場所におけます。)
この時点ではまだ YAML がないので Sync は失敗します。
Pipeline を記述
パイプラインを記述します。
ドキュメントや、サンプルプロジェクトがあるのでそちらを参考にすると良いと思います。
移行後の iutest の YAML はこちら
https://github.com/srz-zumix/iutest/blob/master/jfrog-pipelines.yml
他の CI サービスとちょっと使い方に特徴があるので、その点だけ説明します。
チェックアウトパス
他の CI サービスではソースとなるリポジトリがカレントディレクトリにチェックアウトされることが多いと思いますが、JFrog Pipelines は複数リポジトリをソースにできるので、それぞれのワークスペースにチェックアウトされます。
このパスは「res_{{ resource_name }}_resourcePath」環境変数で取得できるので、ディレクトリを移動してからビルドやテストを行いましょう。
シークレット環境変数
環境変数は「Generic Integration」を追加することで使用できます。
こちらも上記チェックアウトパスと同様に「int_{{ integration_name }}_{{ env_name }}」のような環境変数になっているので注意してください。
例:https://github.com/srz-zumix/ci-specs/blob/1f64ac66f635b6ffeee06db45ae1210bf0fd1c64/jfrog-pipelines.yml#L28
GitHub ステータス更新もパイプライン記述が必要
他の CI サービスでは自動的に GitHub のコミットステータスを更新してくれますが、JFrog Pipelines ではパイプラインに明記しないといけません。(仕組み上しかたがないですが)
やり方は簡単で、「update_commit_status {{ resource_name }}」で現在の execution の状態に合わせてステータスを更新してくれます。
より細かな制御も可能です。詳しくはドキュメントを参照してください。
Sending Build Status to Source Control - JFrog - JFrog Documentation
Sync
パイプラインをコミットしたら Pipeline Sources で Sync が成功するか確認しましょう。
「Pipelines」>「Pipeline Sources」を開き、Status を確認してください。
パイプラインの記述に不備がなければ「Success」になっているはずです。
問題がある場合は一番右のログボタンから何が原因か確認して修正しましょう。
パイプライン実行
Sync できたらいよいよ実行可能です。
PR トリガーは Sync が成功したあとから有効になるので、最初は手動でトリガーするか、空コミットを push するかで起動しましょう。
(パイプライン修正 PR をして修正されたパイプラインで動作を見たいときも同様。改善したい)
手動でトリガーする場合は、「My Pipelines」から実行したいパイプラインを選択し、そこからトリガーするステップを開いて実行するだけです。
結果は履歴から確認できます。
Next
ここまでで JFrog Pipelines でジョブを実行できるようになったと思います。
JFrog Pipelines は他の CI サービスと使い勝手が少し違います。
Jenkins など他の CI と連携したり、複雑なジョブを構築したりしていくことができるようです。ドキュメントがまとまっているのでそちらを参考に挑戦してみてください。
https://www.jfrog.com/confluence/display/JFROG/Get+Started
バッジ
CI サービス恒例のバッジですが、残念ながら見つけられませんでした。
バッジを付ける方法が見つかったら、このブログで紹介します。
最後に
Shippable が終了したのは残念でしたが、JFrog Pipelines で同じように CI できそうです。
また、Shippable のころに使いこなせなかった Assembly Line が使えるようになって、ドキュメントって大事だと改めて気付かされました。
今回は以上。ではでは。